转载请标明出处:
; 本文出自:【明月的博客】为什么要选择Hive
基于Hadoop的大数据的计算/扩展能力
支持SQL like查询语言 统一的元数据管理 简单编程Hive:
Hive 能够对数据进行管理和查询。
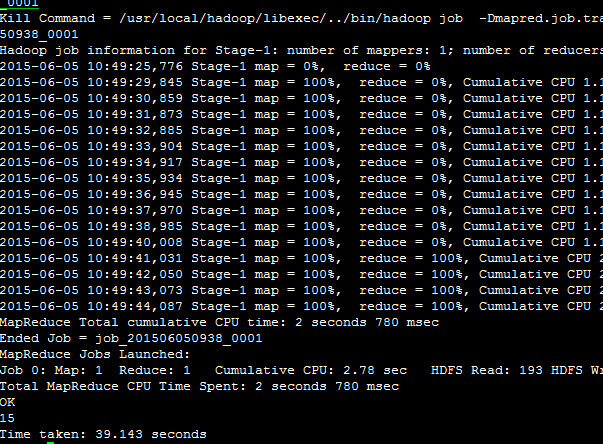
在hadoop生态圈中属于数据仓库的角色。他能够管理hadoop中的数据,同一时候能够查询hadoop中的数据。 本质上讲,hive是一个SQL解析引擎。Hive能够把SQL查询转换为MapReduce中的job来运行。 hive有一套映射工具,能够把SQL转换为MapReduce中的job。能够把SQL中的表、字段转换为HDFS中的文件(夹)以及文件里的列。 这套映射工具称之为metastore。一般存放在derby、mysql中。

Hive的体系结构:
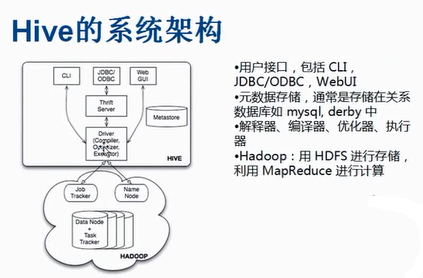
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性是否为外部表等。表的数据所在文件夹等。
解释器、编译器、优化器完毕HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中 。并在随后有MapReduce调用运行。 Hive的数据存储在HDFS中,大部分的查询由MapReduce完毕(包括的查询,像select from table不会生成MapReduce任务)Hive安装
(1) 解压缩、重命名、环境变量设置
(2) 在文件夹 $HIVE_HOME/conf/下。运行命令mv hive-default.xml.template hive-site.xml 重命名
在文件夹$HIVE_HOME/conf/下,运行命令
mv hive-env.sh.template hive-env.sh重命名
(3)改动hadoop的配置文件hadoop-env.sh。改动内容例如以下:
export HADOOP_CLASSPATH=.
:$$CLASSPATH:$HADOOP_CLASSPATH:$HADOOP_HOME/bin
否则启动hive会报找不到类的错误
注意:=右边多了个$,使用时去掉。因为markdown对美元符号处理。会使内容出现故障,所以多加了一个美元符号为了使内容正常显示。
(4)在文件夹$HIVE_HOME/bin以下,改动文件hive-config.sh,添加以下内容:
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/usr/local/hive export HADOOP_HOME=/usr/local/Hadoop
生产中,我们一般用MySQL。不用derby数据库存放metastore.
安装mysql
查看机器是否安了MySQL
rpm -qa | grep mysql
假设存在删除:
rpm -e mysql-libs-5.1.66-2.el6_3.i686
存在依赖能够强制删除
rpm -e mysql-libs-5.1.66-2.el6_3.i686 –nodeps
(1)删除linux上已经安装的mysql相关库信息。
rpm -e xxxxxxx –nodeps
运行命令
rpm -qa |grep mysql
检查是否删除干净
(2)运行命令rpm -i mysql-server-**
安装mysql服务端
(3)启动mysql 服务端,运行命令mysqld_safe &
(4)运行命令
rpm -i mysql-client-**
安装mysqlclient
(5)运行命令mysql_secure_installation
设置root用户password
(6)登陆MySQL。mydsql -uroot -padmin
使用mysql作为hive的metastore
(1)把mysql的jdbc驱动放置到hive的lib文件夹下
(2)改动hive-site.xml文件,改动内容例如以下:javax.jdo.option.ConnectionURL jdbc:mysql://hadoop:3306/hive?createDatabaseIfNotExist=true javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword admin
Mysql 不同意远程连接,怎样让其远程连接:
授权全部权限在hive表上给root用户(不论什么地方的root)。password是admin。grant all on hive.* to ‘root’@’%’ identified by ‘admin’;
之后刷新下:
flush privileges;
内部表
CREATE TABLE t1(id int);
Hive 里没有insert 操作。插入数据方法例如以下:
LOAD DATA LOCAL INPATH ‘/root/id’ INTO TABLE t1;
这样的方式跟hadoop fs –put 命令的方式都能够载入数据。hive 查询识别。
假设去掉local,载入的数据是从hdfs 里载入的。CREATE TABLE t2(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
通过制表符区分字段。
分区表
分区表就是依照不同的字段把文件划分为不同的标准。
CREATE TABLE t3(id int) PARTITIONED BY (day int);
LOAD DATA LOCAL INPATH ‘/root/id’ INTO TABLE t3 PARTITION (day=22);
多了一个文件夹,我们能够依照每天的方式来载入数据。
查的话:
select * from t3 where day=22;
桶表

create table t4(id int) clustered by(id) into 4 buckets;
set hive.enforce.bucketing = true; insert into table t4 select id from t3;
用桶表载入数据要经过MapReduce 计算,不能用load data 方式载入。
值通过哈希编码分到不同的桶中。分到同一桶中的数据非常可能相同。
使用场景:作表连接的时候用。使用文件进行划分,这点与分区表通过文件夹划分不同。
外部表
create external table t5(id int) location ‘/external’;
drop table t5;
优点:删除的时候仅仅删除表定义。数据本身不删除。
前面三个表是受控表。Drop 表时 数据就不存在了。
其它
视图:
跟普通sql 没有什么差别,视图能够屏蔽掉复杂的操作,还能够进行权限的控制,表的操作。视图创建:
CREATE VIEW v1 AS select * from t1;
表的操作:
表的改动:alter table target_tab add columns(cols,string)
表的删除:
drop table
Hive 里能够使用limit 操作:
select * from t1 limit 5;
返回5行记录。
ORDER BY 是全部的数据都送到一个reduce 里进行去全排序。
SORT BY col_list 是多个reduce 运行,在每一个reduce 内部进行排序。DISTRIBUTE BY col_list 把数据分成不同的区发给不同的reduce 去运行。 CLUSTER BY col_list将两种操作合并到一起,相当于sort by 和distribute by一起操作。
表连接:

Java client
Hive 能够编写java程序訪问,訪问时要先启动hive 远程服务:
hive - -service hiveserver >/dev/null 2>/dev/null &
在eclipe 里添加hive jar 包 也必须有hadoop jar包 否则运行不成功
package hive;import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.Statement;public class App { public static void main(String[] args) throws Exception { Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver"); Connection con = DriverManager.getConnection("jdbc:hive://hadoop:10000/default","",""); Statement stmt = con.createStatement(); String sql = "SELECT * FROM default.t1"; ResultSet res = stmt.executeQuery(sql); while(res.next()){ System.out.println(res.getInt(1)); } }} 
Tab键会把关键字显示出来 ,里面带小括号的表示函数
显示全部的函数:
show functions;
函数怎么用,能够:
describe function pi;
查看详细函数的操作。
这里我们统计id的和 ,使用sum函数
select sum(id) from t1;